令和6年秋期試験午後問題 問6
問6 データベース
⇱問題PDF
トレーディングカードの個人間売買サイトの構築に関する次の記述を読んで,設問に答えよ。
トレーディングカードの個人間売買サイトの構築に関する次の記述を読んで,設問に答えよ。
広告
S社は,トレーディングカード販売業のチェーンを営む中堅企業である。トレーディングカードを個人から買い取り,販売する事業を営んでいる。トレーディングカードの個人間の売買が盛んな市場環境を受け,個人間の売買を安心かつ手軽に行える取引プラットフォームをサービスとして提供して,安定的な手数料収入を得る新規事業を立ち上げることにした。S社の情報システム部は新規事業の要となる取引プラットフォームのシステム(以下,本システムという)を新規で構築することになり,Tさんがデータベースの設計及び開発を担当することになった。
〔新規事業の業務要件の確認〕
Tさんは,まず,新規事業において実現する業務要件を確認した。新規事業の業務要件(抜粋)を表1に示す。
 〔概念データモデルの設計〕
〔概念データモデルの設計〕
Tさんは,表1の業務要件に基づいて,E-R図を用いて本システムの概念データモデルを設計した。本システムの概念データモデル(抜粋)を図1に示す。なお,カテゴリの階層構造は,自己参照の関連を用いて表現する。 本システムのデータベースでは,E-R図のエンティティ名を表名にし,属性名を列名にして,適切なデータ型で表定義した関係データベースによって,データを管理する。
本システムのデータベースでは,E-R図のエンティティ名を表名にし,属性名を列名にして,適切なデータ型で表定義した関係データベースによって,データを管理する。
〔SQLの作成〕
Tさんは,表1の項番2の業務要件を実現するための検索のSQL文を作成した。作成したSQL文を図2に示す。なお,":カテゴリID",":下限価格",":上限価格",":商品状態",":出品状況",":キーワード"は,該当の値を格納する埋込み変数である。また,最上位であるカテゴリの上位カテゴリIDにはNULLが設定されている。 〔性能の検証と改善〕
〔性能の検証と改善〕
Tさんがテストデータを用いて図2のSQL文の実行性能を検証したところ,実行を開始してから検索結果が得られるまでの処理時間が長く,実用的ではないことが判明した。
本システムでは出品される商品の数が膨大であり,利用者が図2のSQL文を頻繁に実行することが予想される。そこで,Tさんはキーワードでの検索が必要な商品名及び商品説明の列には全文検索エンジンを用いるとともに,その他の列に対しては適切なインデックスを設定し,性能上の懸念を解消することを検討した。
インデックスの方式には,B-treeインデックスを採用することにした。Tさんは,各表の表定義を確認し,インデックスを設定すべき列を検討した。出品表の表定義を表2に,カテゴリ表の表定義を表3に示す。
表2及び表3のデータ型欄は,データ型,長さ,精度,位取りを示す。PK欄は主キー制約,UK欄はUNIQUE制約,非NULL欄は非NULL制約の指定をするかどうかを示す。指定する場合にはYを,指定しない場合にはNが記入されている。ここで,主キーに対してはUNIQUE制約は指定せず,非NULL制約は指定するものとする。カーディナリティ欄は列に多数の異なる値をもつ場合には高を,少数の異なる値をもつ場合には低を記入する。そして,高と低の中間の数の異なる値をもつ場合には中を記入する。データ分布欄は列に含まれる値の確率分布の仮定を示す。
Tさんは,①B-treeインデックスの特性を踏まえて,特定の値を指定したときに行数を表全体の5%以下に絞り込める列だけにインデックスを設定することにした。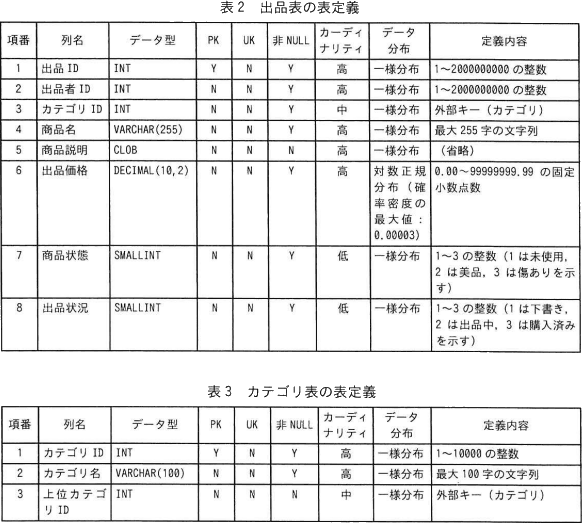 Tさんは,必要なインデックスを設定後にテストデータを用いて図2のSQL文の実行性能を検証し,実用的な性能であることを確認した。ただし,表2及び表3のデー夕分布は新規事業立上げ前の時点における仮定でしかない。今後実際に運用する際にはデータ分布が仮定とは異なる場合があるので,定期的にインデックスを見直すことを申し送り事項の一つとして,本システムのデータベースの設計及び開発を完了した。
Tさんは,必要なインデックスを設定後にテストデータを用いて図2のSQL文の実行性能を検証し,実用的な性能であることを確認した。ただし,表2及び表3のデー夕分布は新規事業立上げ前の時点における仮定でしかない。今後実際に運用する際にはデータ分布が仮定とは異なる場合があるので,定期的にインデックスを見直すことを申し送り事項の一つとして,本システムのデータベースの設計及び開発を完了した。
〔新規事業の業務要件の確認〕
Tさんは,まず,新規事業において実現する業務要件を確認した。新規事業の業務要件(抜粋)を表1に示す。
Tさんは,表1の業務要件に基づいて,E-R図を用いて本システムの概念データモデルを設計した。本システムの概念データモデル(抜粋)を図1に示す。なお,カテゴリの階層構造は,自己参照の関連を用いて表現する。
〔SQLの作成〕
Tさんは,表1の項番2の業務要件を実現するための検索のSQL文を作成した。作成したSQL文を図2に示す。なお,":カテゴリID",":下限価格",":上限価格",":商品状態",":出品状況",":キーワード"は,該当の値を格納する埋込み変数である。また,最上位であるカテゴリの上位カテゴリIDにはNULLが設定されている。
Tさんがテストデータを用いて図2のSQL文の実行性能を検証したところ,実行を開始してから検索結果が得られるまでの処理時間が長く,実用的ではないことが判明した。
本システムでは出品される商品の数が膨大であり,利用者が図2のSQL文を頻繁に実行することが予想される。そこで,Tさんはキーワードでの検索が必要な商品名及び商品説明の列には全文検索エンジンを用いるとともに,その他の列に対しては適切なインデックスを設定し,性能上の懸念を解消することを検討した。
インデックスの方式には,B-treeインデックスを採用することにした。Tさんは,各表の表定義を確認し,インデックスを設定すべき列を検討した。出品表の表定義を表2に,カテゴリ表の表定義を表3に示す。
表2及び表3のデータ型欄は,データ型,長さ,精度,位取りを示す。PK欄は主キー制約,UK欄はUNIQUE制約,非NULL欄は非NULL制約の指定をするかどうかを示す。指定する場合にはYを,指定しない場合にはNが記入されている。ここで,主キーに対してはUNIQUE制約は指定せず,非NULL制約は指定するものとする。カーディナリティ欄は列に多数の異なる値をもつ場合には高を,少数の異なる値をもつ場合には低を記入する。そして,高と低の中間の数の異なる値をもつ場合には中を記入する。データ分布欄は列に含まれる値の確率分布の仮定を示す。
Tさんは,①B-treeインデックスの特性を踏まえて,特定の値を指定したときに行数を表全体の5%以下に絞り込める列だけにインデックスを設定することにした。
広告
設問1
図1中のa~dに入れる適切なエンティティ間の関連及び属性名を答え,概念データモデルを完成させよ。なお,エンティティ間の関連及び属性名の表記は,図1の凡例に倣うこと。
解答例・解答の要点
a: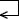
b:-
c:追跡番号
d:→
b:-
c:追跡番号
d:→
解説
〔aについて〕〔概念データモデルの設計〕の記述には「カテゴリの階層構造は,自己参照の関連を用いて表現する」とあります。つまり、カテゴリエンティティの主キー(カテゴリID)が、同エンティティの外部キーである属性(上位カテゴリID)から参照される形になるということです。表1項番1の業務要件には「カテゴリはトレーディングカードのブランドやシリーズによって階層化されている」とあることから、同一の上位カテゴリIDをもつ複数のレコードが存在しえることがわかります。したがって、空欄aには「
」が当てはまります。なお、下から上に向けた自己参照の矢印でも問題ありません。
∴a=
〔bについて〕
発送エンティティと取引エンティティには共通の属性"取引ID"があります。この属性"取引ID"は、取引エンティティ側では主キーであり、取引を一意に特定します。また、発送エンティティ側では外部キーです。表1項番5には業務要件として「一つの取引に関する商品を分割して発送することや,複数の取引に関する商品をまとめて発送することはできない」とあることから、取引と発送が1対1で対応することになります。発送エンティティには同一の取引IDをもつ複数のレコードは存在しえないので、発送エンティティと取引エンティティのカーディナリティは1対1です。したがって、空欄bには「―」が当てはまります。
∴b=―
〔cについて〕
表1項番5の業務要件には「S社は発送した商品の追跡番号を管理し,…」とあることから、発送に関するデータとして"追跡番号"をもつ必要がありますが、発送エンティティその他を見てもそのような属性はありません。したがって必要となる属性は「追跡番号」であり、これが空欄cにはが当てはまります。
∴c=追跡番号
〔dについて〕
フォローエンティティの(複合)主キーは"フォロー元利用者ID"、"フォロー先利用者ID"の組であり、利用者間のフォロー関係を一意に特定します。フォローエンティティの属性"フォロー元利用者ID"、"フォロー先利用者ID"はそれぞれ、利用者エンティティの主キー"利用者ID"を参照していると考えられます。ある利用者が複数の利用者をフォローすることが想定されるため、フォローエンティティには同一のフォロー元利用者IDをもつ複数のレコードが存在すると考えられます。同様に、ある利用者が複数の利用者にフォローされることが想定されるため、フォローエンティティには同一のフォロー先利用者IDをもつ複数のレコードが存在すると考えられます。よって、利用者エンティティとフォローエンティティのカーディナリティは、フォロー元利用者ID側もフォロー先利用者IDいずれも1対多です。したがって、空欄dには「→」が当てはまります。
原則として、ある主キーをもつエンティティと、その主キーを外部キーに持つエンティティのカーディナリティ(多重度)は「1対多」です。
∴d=→
広告
設問2
図2中のe~hに入れる適切な字句又は式を答えよ。
解答例・解答の要点
e:WITH RECURSIVE
f:UNION ALL
g:出品.カテゴリID = 指定カテゴリ.カテゴリID
h:LIKE '%' || :キーワード || '%'
f:UNION ALL
g:出品.カテゴリID = 指定カテゴリ.カテゴリID
h:LIKE '%' || :キーワード || '%'
解説
表1項番2の業務要件では「(検索で)カテゴリを指定する場合,指定されたカテゴリ及びその下位にある全てのカテゴリの出品が検索対象となる」とあります。図2のSQL文は、この要件を満たすために作成されています。このSQLは新たな表を定義する部分と、その表を使って検索を行うという2つの文で構成されています。解答のうえで特に注目すべき部分は次の箇所です。

図2を見ると、①のSQL文では「指定カテゴリ」という表を仮に定義していて、②のSQL文ではその定義された表を検索対象としていることが確認できます。このようにSQL文の実行結果を一時的な表として名前付きで定義し、それを後続のSQL文で利用するにはWITH句(共通テーブル式:CTE)を使用します。さらに、指定カテゴリ表は自分自身を参照する再帰的な構造となっています。WITH句内の共通テーブル式がそれ自体を参照するような表を作成する場合には、WITH句を拡張したWITH RECURSIVE句を使用する必要があります。
WITH RECURSIVE句の構文は次のとおりです。UNION ALLもしくはUNIONで区切られた2つの部分で構成されます。
WITH RECURSIVE 仮想テーブル名(列名1, 列名2, …) AS (
《非再帰的なSELECT文》
UNION [ALL]
《再帰的なSELECT文》
)
《非再帰的なSELECT文》は初期レコードを取得するもので仮想テーブルを参照しない、《再帰的なSELECT文》は仮想テーブルを自己参照して追加レコードを取得するという役割の違いがあります。WITH RECURSIVE句は次のように動作します。《非再帰的なSELECT文》
UNION [ALL]
《再帰的なSELECT文》
)
- 《非再帰的なSELECT文》が、仮想テーブルの初期レコードを取得する
- 《再帰的なSELECT文》が、現在の仮想テーブルを参照して結果を返す。返された結果が新たな仮想テーブルとなる
- 《再帰的なSELECT文》の結果が0件になるまで②を繰り返す
- UNION ALL句により、初期レコードと《再帰的なSELECT文》で取得された結果すべてが統合されて最終的な仮想テーブルとなる
したがって、空欄eには「WITH RECURSIVE」が、空欄fには「UNION ALL」が当てはまります。なお、各SQL文の結果には重複するレコードが含まれていないため、UNIONを使用しても同じ結果になります。ただし、パフォーマンス面や実務の視点※からは、UNION ALLの方がより適切な解答と言えます。
∴e=WITH RECURSIVE
f=UNION ALL
※試験問題および標準SQLの仕様上は、UNION (DISTINCT)でも問題はありません。ただし、実際のSQL実行においては、重複行の削除と再帰処理の実行順序はRDBMSの実装に依存しており、場合によっては無限ループを引き起こす可能性があるため推奨されません。実務上はUNION ALLの使用が推奨されます。
参考URL: https://stackoverflow.com/questions/47998833/why-does-a-recursive-cte-in-transact-sql-require-a-union-all-and-not-a-union
【補足】
WITH RECURSIVEの動作を具体例で確認しましょう。仮にカテゴリ表が以下で、:カテゴリIDが2だとします。
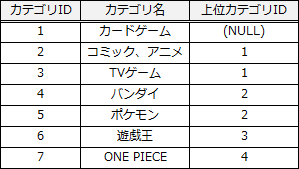



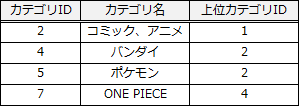
FROM句に出品表、INNER JOIN句にはWITH RECURSIVE文で作成した指定カテゴリ表が指定されているので、空欄には2つのテーブルを結合するための条件が入ります。指定カテゴリ表は、指定されたカテゴリとその下位のカテゴリの一覧表であり、出品表とカテゴリ表は、"カテゴリID"列によって関連付けられていますから、"カテゴリID"列で結合すればそれらのカテゴリに該当する出品を取得できると考えられます。したがって、空欄gには「出品.カテゴリID = 指定カテゴリ.カテゴリID」が当てはまります。
∴g=出品.カテゴリID = 指定カテゴリ.カテゴリID
〔hについて〕
表1項番2の業務要件には「キーワードは,商品名及び商品説明を部分一致で検索したい場合に指定する」とあることから、この検索条件をWHERE句に追加する必要があります。部分一致検索とは、文字列の部分として対象語句を含む値を検索するもので、LIKE句を使用した次の構文を指定して行います。
WHERE 列名 LIKE '%語句%'
%はワイルドカードと呼ばれ、0文字以上の任意の文字列にマッチする特殊文字です。対象語句の前後に付けることで部分一致検索となります。〔SQLの作成〕には「":キーワード"は,該当の値を格納する埋込み変数である」と記述されているので、上記の語句の部分に":キーワード"を当てはめる必要があります。埋込み変数の値を展開するためには、%と:キーワードと%を文字列結合しなければなりません。標準SQLでは||(パイプ演算子)を使って文字列結合を行うので、空欄hには「LIKE '%' || :キーワード || '%'」が当てはまります。
なお、WHERE 出品.商品名 LIKE '%:キーワード%'だと、":キーワード"という語句で部分一致検索されてしまうため誤りです。また、||は標準SQLにおける文字列結合の演算子ですが、使用するDBMSによっては+やCONCAT関数を用いるケースもあります。
∴h=LIKE '%' || :キーワード || '%'
広告
設問3
〔性能の検証と改善〕について答えよ。
- 本文中の下線①について,B-treeインデックスの特性として適切なものを解答群の中から三つ選び,記号で答えよ。
- 出品表及びカテゴリ表のそれぞれについて,表2及び表3を基に,B-treeインデックスを設定することで図2のSQL文の実行性能の高速化に寄与する列名を全て答えよ。なお,本システムで使用する関係データベースでは,主キーに対して自動的にインデックスが設定される。
解答群
- インデックスを設定した各列に対する条件をAND演算子で組み合わせた検索は高速化できるが,NOT演算子を用いた条件による検索は高速化できない。
- インデックスを設定した列に対して演算や型変換を行った上で検索条件に指定した場合,検索を高速化できる。
- インデックスを設定した列に含まれる値の分布に偏りがない場合,検素性能が安定する。
- カーディナリティが低い列にインデックスを設定すると,検索を高速化できる。
- 行数nの表において,特定の行を検索するときの計算量はO(log n)である。
- 行数nの表において,特定の行を挿入するときの計算量はO(n)である。
- 等号演算子を用いた条件による検索は高速化できるが,値の範囲を指定した条件による検索は高速化できない。
解答例・解答の要点
- ア,ウ,オ
- 出品表:カテゴリID,出品価格
カテゴリ表:上位カテゴリID
解説
- B-tree(B木)は、すべての葉ノードの深さが一定であり、1つの節点に複数の値を持つことができる平衡多分木の木構造です。B-treeインデックスはB木を使用したインデックス法で、その改良版のB+木インデックスとともにRDBMSでよく使用されます。すべての葉ノードが同じ深さにあるため、検索・挿入・削除のいずれの操作もO(log n)の計算量で安定して処理でき、パフォーマンスの一貫性が保証されるのが特徴です。
B-treeインデックスは、次のようなもつ列に対して設定するとクエリの高速化が期待できます。- 一致検索(=、LIKE※、IS [NOT] NULL)が行われる
※前方一致、完全一致に限る - 範囲検索(>、<、>=、<=、BETWEEN)が行われる
- 値の重複が少ない(=カーディナリティが高い)
- 正しい。検索対象の各列にインデックスが設定されている場合、検索時にそれぞれのインデックスを活用することでAND条件の絞り込みが効率的に行われ、検索が高速化されます。また、複数列で構成される「結合(複合)インデックス」を設定すれば、検索パフォーマンスをさらに向上させることが可能です。一方、NOT演算子を使った検索では、条件に合わないデータを探すために全件スキャンが必要になります。この場合、インデックスは利用されず検索の高速化はできません。
- インデックスは元の列の値に基づいて構築されています。インデックスが設定された列に対して演算(加算や関数の適用)や型変換をした場合、列の元の値と直接比較できません。このため、インデックスは利用されず検索の高速化はできません。
- 正しい。インデックスを設定した列に含まれる値の分布に偏りがなければ、各値に対応するレコード数もほぼ等しく、B木に均等に分布していることになります。そのため、どの値を対象に検索しても検索時間に大きな差はありません。
- 高速化できるのは、カーディナリティが高い列に設定した場合です。カーディナリティが低い列(=同じ値がたくさん含まれる列)では、インデックスで絞り込んでも候補となる行が大量に返されます。返された行を全行スキャンする必要があるため、検索の高速化は限定的です。
- 正しい。B-treeインデックスは平衡木構造であるため、探索時の比較回数は木の高さに比例します。B木の深さは各節点が持つエントリ数(次数)で決まり、次数がb、深さがhであるB木がもてる葉ノード数nは「n=bh」の式で表せます。この式より、葉ノード数nで次数がbであるB木の深さhは「h=logbn」です。したがって、探索における計算量のオーダーは対数時間:O(log n)となります。
- 行を挿入する際には、適切な挿入位置を見つけるために検索を行う必要があります。検索・挿入・削除に要する計算量はほぼ等しく、対数時間:O(log n)に収まります。
- 等号演算子(=)を用いた一致検索、範囲検索のどちらも高速化できます。
- 一致検索(=、LIKE※、IS [NOT] NULL)が行われる
- まず、本文および設問に記載されている除外条件を整理します。
- 主キーに対して自動的にインデックスが設定される
- キーワードでの検索が必要な商品名及び商品説明の列には全文検索エンジンを用いる
【出品表】
残った列は、カテゴリID、出品価格、商品状態、出品状況です。
商品状態と出品状況はカーディナリティが"低"で、それぞれ取る値が3種類しかないので不適です。出品価格はBETWEEN検索をしていて、カーディナリティが"高"なので適しています。カテゴリIDはカーディナリティが"中"ですが、行数を5%以下に絞り込めるという条件を考慮した場合、カテゴリIDは少なくとも20種類以上はあること、一様分布であることから5%以下に絞込み可能と言えます。したがって「出品価格、カテゴリID」の組が適切です。
【カテゴリ表】
残った列は、上位カテゴリIDのみです。
上位カテゴリIDはカーディナリティが"中"ですが、前述したカテゴリIDと同じ理由で5%以下に絞込みが可能です。したがって「上位カテゴリID」が適切です。
∴出品表=カテゴリID,出品価格
カテゴリ表=上位カテゴリID
【補足】
出品価格のデータ分布である対数正規分布は、小さい値の範囲にデータが多く集まり、最も頻度の高い値(ピーク)を過ぎると、大きな値に向かってデータ数がゆるやかに減少していく分布です(右に長く伸びた形状)。出品価格に当てはめると低価格帯が圧倒的に多いものの、中価格・高価格帯も一定数あるという状態を示します。
広告

広告