
応用情報技術者過去問題 令和7年春期 午後問4
⇄問題文と設問を画面2分割で開く⇱問題PDF問4 システムアーキテクチャ
ビルエネルギーマネジメントシステムの非機能要件に関する次の記述を読んで,設問に答えよ。
E社は,オフィスビルのエネルギー使用量を一元管理するビルエネルギーマネジメントシステム(以下,BEMSという)を開発・運用している企業である。首都圏を中心に複数のオフィスビルを所有しているR社に対して,オンプレミス方式のBEMS(以下,オンプレBEMSという)を運用してきた。最近,R社から"複数のオフィスビルのオンプレBEMSを統合管理したい"という要望があり,E社はクラウド方式のBEMS(以下,クラウドBEMSという)を提案することになった。
オンプレBEMSは,BEMSサーバ,BEMSクライアント及びBEMSゲートウェイで構成され,E社はこれらの設置・運用を行っている。ビル管理員はBEMSクライアント上のWebブラウザを用いてBEMSサーバにアクセスし,BEMSゲートウェイを介して照明機器や空調機器などの制御対象機器の制御や監視を行う。オンプレBEMSは複数のR社オフィスビルに導入されている。
オンプレBEMSを用いた既存システム(以下,既存システムという)の構成の一部を図1に示す。なお,図1の各R社オフィスビルでは,制御対象機器を接続するビル制御LANと,BEMSサーバやBEMSクライアントを接続するビル管理LANとが既設されており,二つのLANをBEMSゲートウェイで接続している。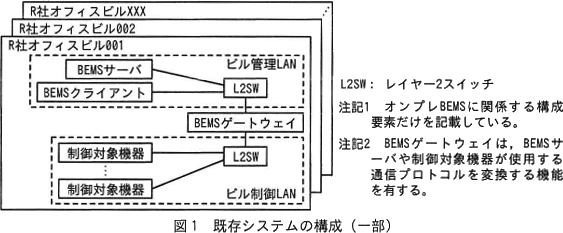 E社は,R社の各オフィスビルに設置している既存システムから,複数のオフィスビルを統合管理できるクラウドBEMSを用いた新システム(以下,新システムという)へ移行する方法を検討した。新システムでは,ビル管理員はR社運用拠点のBEMSクライアントから,E社が別途サービスを提供しているIaaS型クラウドサービス(以下,E社クラウド基盤サービスという)の仮想サーバ上に構築したBEMSサーバを操作し,ファイアウォール(以下,FWという)とBEMSゲートウェイを介して制御対象機器の制御や監視を行う。E社はBEMSサーバ,BEMSクライアント及びBEMSゲートウエイを設置・運用する。FW及びインターネット接続環境はR社が設置・運用する。新システムの構成案の一部を図2に示す。
E社は,R社の各オフィスビルに設置している既存システムから,複数のオフィスビルを統合管理できるクラウドBEMSを用いた新システム(以下,新システムという)へ移行する方法を検討した。新システムでは,ビル管理員はR社運用拠点のBEMSクライアントから,E社が別途サービスを提供しているIaaS型クラウドサービス(以下,E社クラウド基盤サービスという)の仮想サーバ上に構築したBEMSサーバを操作し,ファイアウォール(以下,FWという)とBEMSゲートウェイを介して制御対象機器の制御や監視を行う。E社はBEMSサーバ,BEMSクライアント及びBEMSゲートウエイを設置・運用する。FW及びインターネット接続環境はR社が設置・運用する。新システムの構成案の一部を図2に示す。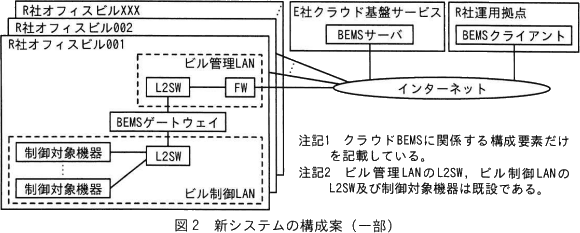 〔品質要件の検討〕
〔品質要件の検討〕
E社は,図2の構成案をR社に提案した。BEMSを新たなビルに導入する場合,既存システムでは,オフィスビルごとにBEMSサーバ,BEMSクライアント及びBEMSゲートウェイをそれぞれ導入する必要があった。一方,新システムでは,FW及びインターネット接続環境をR社が設置・運用すれば,E社がR社オフィスビル側にaを設置することによってBEMSを導入できる。R社が要望した統合管理が実現でき,さらにBEMS導入が比較的容易になることから,R社は新システムへの移行検討の具体化をE社に依頼した。
E社の提案に対して,R社から次の要望が出された。 表1の項番1について,既存システムではBEMSサーバのメンテナンスのたびに計画停止が必要であった。新システムでは,E社クラウド基盤サービス上でBEMSサーバを仮想サーバとして構築できることを生かして,2台のBEMSサーバをd構成にすれば,計画停止をなくすことができる。そこで,図2の構成案に対して,E社クラウド基盤サービス上で,BEMSサーバを1台追加する。
表1の項番1について,既存システムではBEMSサーバのメンテナンスのたびに計画停止が必要であった。新システムでは,E社クラウド基盤サービス上でBEMSサーバを仮想サーバとして構築できることを生かして,2台のBEMSサーバをd構成にすれば,計画停止をなくすことができる。そこで,図2の構成案に対して,E社クラウド基盤サービス上で,BEMSサーバを1台追加する。
表1の項番2について,既存システムのBEMSサーバのハードウェア障害発生時には,保守サービス会社への連絡,保守員の駆けつけ,障害箇所の確認,ハードウェア交換,バックアップからのデータ復旧,サービスの再開,という手順で回復していた。この手順のうち,BEMSサーバがオフィスビル内に設置されていることに起因して保守員の駆けつけに要する時間が長かったが,新システムではBEMSサーバが配置されるE社クラウド基盤サービスの拠点に保守員が常駐するので,保守員の駆けつけに要する時間は大幅に短縮される。加えて,仮想サーバに障害が発生したときでも速やかにサービスを再開できるように,新システムではE社クラウド基盤サービスのe機能を活用して構成する。
〔クラウドサービス障害発生時の新システムへの影響〕
新システムでは,仮想サーバで構築したBEMSサーバのハードウェア障害発生時の平均サービス回復時間について大幅に短縮できることが確認できたが,E社クラウド基盤サービスに障害が発生した場合の,新システムに対する影響について,R社から説明を求められた。E社クラウド基盤サービスでは,仮想サーバを直接利用する顧客との契約時にサービスレベル合意書(以下,SLAという)を締結しているので,当該SLAの内容を引用して,どの程度の影響が新システムに及ぶかを説明することにした。E社クラウド基盤サービスのSLAの一部を図3に示す。 E社は新システムで重要な機能を担うBEMSサーバを例として取り上げ,そこで障害が発生した場合の影響について説明する資料を,追加で作成することにした。当該資料には,図3のE社クラウド基盤サービスのSLAの内容に加えて,月間サービス稼働率を満たした場合に月間累積障害時間がg分以内になることや,①月間サービス接働率が99.5%になった場合に減額される金額など,具体的な事例を記載することにした。また,当該資料にはBEMSサーバのハードウェア,ソフトウェア及びネットワークに発生する可能性がある障害の要因を示し,②図3のE社クラウド基盤サービスのSLAで保証されない要因について説明を加えることにした。
E社は新システムで重要な機能を担うBEMSサーバを例として取り上げ,そこで障害が発生した場合の影響について説明する資料を,追加で作成することにした。当該資料には,図3のE社クラウド基盤サービスのSLAの内容に加えて,月間サービス稼働率を満たした場合に月間累積障害時間がg分以内になることや,①月間サービス接働率が99.5%になった場合に減額される金額など,具体的な事例を記載することにした。また,当該資料にはBEMSサーバのハードウェア,ソフトウェア及びネットワークに発生する可能性がある障害の要因を示し,②図3のE社クラウド基盤サービスのSLAで保証されない要因について説明を加えることにした。
E社は,オフィスビルのエネルギー使用量を一元管理するビルエネルギーマネジメントシステム(以下,BEMSという)を開発・運用している企業である。首都圏を中心に複数のオフィスビルを所有しているR社に対して,オンプレミス方式のBEMS(以下,オンプレBEMSという)を運用してきた。最近,R社から"複数のオフィスビルのオンプレBEMSを統合管理したい"という要望があり,E社はクラウド方式のBEMS(以下,クラウドBEMSという)を提案することになった。
オンプレBEMSは,BEMSサーバ,BEMSクライアント及びBEMSゲートウェイで構成され,E社はこれらの設置・運用を行っている。ビル管理員はBEMSクライアント上のWebブラウザを用いてBEMSサーバにアクセスし,BEMSゲートウェイを介して照明機器や空調機器などの制御対象機器の制御や監視を行う。オンプレBEMSは複数のR社オフィスビルに導入されている。
オンプレBEMSを用いた既存システム(以下,既存システムという)の構成の一部を図1に示す。なお,図1の各R社オフィスビルでは,制御対象機器を接続するビル制御LANと,BEMSサーバやBEMSクライアントを接続するビル管理LANとが既設されており,二つのLANをBEMSゲートウェイで接続している。
E社は,図2の構成案をR社に提案した。BEMSを新たなビルに導入する場合,既存システムでは,オフィスビルごとにBEMSサーバ,BEMSクライアント及びBEMSゲートウェイをそれぞれ導入する必要があった。一方,新システムでは,FW及びインターネット接続環境をR社が設置・運用すれば,E社がR社オフィスビル側にaを設置することによってBEMSを導入できる。R社が要望した統合管理が実現でき,さらにBEMS導入が比較的容易になることから,R社は新システムへの移行検討の具体化をE社に依頼した。
E社の提案に対して,R社から次の要望が出された。
- 既存システムでは,BEMSサーバをメンテナンスする際に実施する計画停止の頻度が高く不便だったので,新システムでは計画停止の頻度を低くしてほしい。
- 既存システムでは,BEMSサーバのハードウェア障害の発生頻度は低いものの,障害発生時のシステム停止時間が長く不便だったので,新システムではできるだけ短くしてほしい。
表1の項番2について,既存システムのBEMSサーバのハードウェア障害発生時には,保守サービス会社への連絡,保守員の駆けつけ,障害箇所の確認,ハードウェア交換,バックアップからのデータ復旧,サービスの再開,という手順で回復していた。この手順のうち,BEMSサーバがオフィスビル内に設置されていることに起因して保守員の駆けつけに要する時間が長かったが,新システムではBEMSサーバが配置されるE社クラウド基盤サービスの拠点に保守員が常駐するので,保守員の駆けつけに要する時間は大幅に短縮される。加えて,仮想サーバに障害が発生したときでも速やかにサービスを再開できるように,新システムではE社クラウド基盤サービスのe機能を活用して構成する。
〔クラウドサービス障害発生時の新システムへの影響〕
新システムでは,仮想サーバで構築したBEMSサーバのハードウェア障害発生時の平均サービス回復時間について大幅に短縮できることが確認できたが,E社クラウド基盤サービスに障害が発生した場合の,新システムに対する影響について,R社から説明を求められた。E社クラウド基盤サービスでは,仮想サーバを直接利用する顧客との契約時にサービスレベル合意書(以下,SLAという)を締結しているので,当該SLAの内容を引用して,どの程度の影響が新システムに及ぶかを説明することにした。E社クラウド基盤サービスのSLAの一部を図3に示す。
設問1
〔品質要件の検討〕について答えよ。
- 本文中のaに入れる適切な構成要素名を図2中から選び答えよ。
- 表1中のb,cに入れる適切な字句を解答群の中から選び,記号で答えよ。
- 本文中のd,eに入れる適切な字句を解答群の中から選び,記号で答えよ。
b,c に関する解答群
- 移行性
- 運用・保守性
- 可用性
- 性能・拡張性
d,e に関する解答群
- CASB
- RAID5
- VPN
- アクティブ-スタンバイ
- クライアントサーバ
- シンクライアント
- ピアツーピア
- ライブマイグレーション
解答入力欄
- a:
- b:
- c:
- d:
- e:
解答例・解答の要点
- a:BEMSゲートウェイ
- b:イ
- c:ウ
- d:エ
- e:ク
解説
- 〔aについて〕
E社が設置する機器は、BEMSサーバ、BEMSクライアント、BEMSゲートウェイです。図2を見ると、既存ではビルごとにあったBEMSサーバとBEMSクライアントは、新システムではクラウドとR社拠点に置かれ、複数のオフィスで共用されます。一方で、BEMSゲートウェイはこれまでと同じくR社ネットワークに置かれています。
図2中にはBEMSゲートウェイのほかにもいくつかの機器がありますが、図2注記2には「ビル管理LANのL2SW,ビル制御LANのLS2W及び制御対象機器は既設である」、本文中には「FW及びインターネット環境はR社が設置・運用する」とあります。この条件より、E社がR社のオフィスビルに設置すべき機器は「BEMSゲートウェイ」に絞られます。したがって、空欄aには「BEMSゲートウェイ」が入ります。
∴a=BEMSゲートウェイ - 非機能要件とは、機能要件以外の要件のことで、可用性、性能・拡張性、運用・保守性、移行性、セキュリティ、システム環境・エコロジーなど、主にシステムの品質に関する要件のことです。
表1の非機能要件の指標値は、R社から以下2つのの要望を受けて確認されたものです。- 既存システムでは,BEMSサーバをメンテナンスする際に実施する計画停止の頻度が高く不便だったので,新システムでは計画停止の頻度を低くしてほしい
- 既存システムでは,BEMSサーバのハードウェア障害の発生頻度は低いものの,障害発生時のシステム停止時間が長く不便だったので,新システムではできるだけ短くしてほしい
表1の項番2「BEMSサーバのハードウェア障害時のサービス回復時間」は、2つ目の要望に対応します。システムの利用可能時間に関する要求なので、分類は「可用性」です。よって、空欄bには「イ」、空欄cには「ウ」が当てはまります。
∴b=イ:運用・保守性
c=ウ:可用性
【補足】
項番2にある平均サービス回復時間(MTRS:Mean Time To Restore Service)は、サービスマネジメント分野で保守性を測る指標とされています。本問の内容だけだと判断がつきにくく、問題としてはあまり良いとは言えません。IPAの非機能要件グレードでは区分ごとの要求項目を以下のように定義しており、非機能要件の分類から考えると出題の出所はこれだと考えられます。
- ここで提示されている8つの選択肢の内容は以下のとおりです。
- CASB(Cloud Access Security Broker)
- 組織内のクラウドサービスの利用状況を一元的に可視化・制御し、セキュリティ対策を行うソフトウェア
- RAID5
- データとパリティビット両方を各ディスクに分散して書き込むことで、信頼性とアクセス性能を高めるストレージ冗長化技術
- VPN(Virtual Private Network)
- 認証と暗号技術を利用してインターネット上に仮想的な専用の通信経路を構築し、セキュリティの高い通信を可能にする技術
- アクティブ-スタンバイ
- 同じ機能を持つ2台のサーバを用意し、一方は通常稼働している「アクティブ」な状態で、もう一方は待機している「スタンバイ」状態とする方式。アクティブなシステムに障害が発生した場合、スタンバイのシステムが即座に稼働を開始し、サービスの継続性を確保する
- クライアントサーバ
- サービスを利用するクライアントと、サービスを提供するサーバで構成される分散処理システムの方式
- シンクライアント
- 端末にはデータやアプリケーションを置かず、サーバ側ですべての情報を管理する方式
- ピアツーピア
- ネットワーク上の端末同士が対等な立場で、相互にクライアントやサーバの役割を果たしてデータをやり取りする方式
- ライブマイグレーション
- 物理サーバ上で稼働している仮想マシン(VM)を、稼働させたまま別の物理サーバに差し替え、処理をシームレスに継続させる技術
定期メンテナンスそのものの実施は避けられません。適切なメンテナンスを実施しつつ、計画停止をなくすためには、サーバを冗長構成にし保守中でももう一方でシステムが稼働できる仕組みが必要です。空欄dの前には「2台のBEMSサーバで」とあるので、これに該当する構成方式は「アクティブ-スタンバイ」です。
∴d=エ:アクティブ-スタンバイ
〔eについて〕
空欄eの前にある「仮想サーバに障害が発生したときでも速やかにサービスを再開できる」という説明より、「ライブマイグレーション」が該当します。ライブマイグレーションでの切替えはダウンタイムが極めて小さく、移動前の処理やセッションがすべて引き継がれるため可用性を損なうことがありません。
∴e=ク:ライブマイグレーション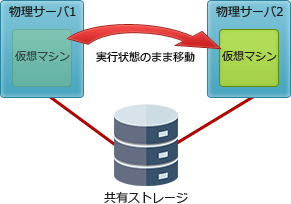
設問2
〔クラウドサービス障害発生時の新システムへの影響〕について答えよ。
f に関する解答群
- 稼働
- 待機
- 超過
- 停止
解答群
- CPUの障害
- ストレージの障害
- ソフトウェアの障害
- ネットワークの障害
解答入力欄
- f:
- g: 分
- 円
解答例・解答の要点
- f:ア
- g:22
- 900
- ウ
解説
- 〔fについて〕
月間サービス稼働率は、サービスを予定している総時間(予定稼働時間)に対して、実際にサービスが稼働した時間(実稼働時間)の割合です。実稼働時間は、予定稼働時間から障害時間を除いた時間なので以下の算式となります。
月間サービス稼働率=月間総稼働予定時間-月間累積障害時間月間総稼働予定時間
空欄fには「ア:稼働」が当てはまります。
∴f=ア:稼働 - 〔gについて〕
月間サービス稼働率99.95%を満たすために許容される障害時間を求めます。1カ月を30日とみなし、答えは"分"で求めることから、
月間総稼働予定時間=30×24×60=43,200(分)
目標値は99.95%以上であるため、許容される障害時間の割合は「1-99.95%=0.05%=0.0005」です。
月間累積障害時間≦43,200×0.0005=21.6(分)
小数第1位を四捨五入するので、正解は「22分」となります。
∴g=22 - 図3の「減額対応」には、「月間サービス稼働率が99.95%に満たなかった場合に,SLAに示す稼働率を達成するための稼働時間よりも少なかった稼働時間に相当する利用料金を減額する」とあります。
月間サービス稼働率が99.95%より少なくなった場合に、月額料金20万円からの減額が発生します。したがって月間サービス稼働率が99.5%の時の返金額は、以下のように計算できます。- SLAで示す稼働率:99.95%
- 実際の稼働率:99.5%
- 両者の差異:99.95%-99.5%=0.45%
200,000×0.0045=900(円)
∴900 - BEMSサーバの配置されるE社クラウド基盤サービスは、E社が別途提供しているIaaS型クラウドサービスです。
IaaS(Infrastructure as a Service)では、ハードウェア(CPU・メモリ・ストレージ)、ネットワークなどの基礎的なコンピュータリソースがサービスの形で提供されます。これらの構成要素および仮想環境を動作させるホストOSや管理用ソフトウェアは事業者の責任で構築・運用され、それに起因する障害はSLAで保証されます。一方、利用者は仮想環境のゲストOS・ミドルウェア・アプリケーションなど、すべてのソフトウェアを自ら導入・管理します。クラウドサービスでは、利用者が手を加えられない部分は事業者責任、自由に変更できる部分は利用者責任になるというのが基本的な考え方です。したがって、SLAで保証されないのは、IaaS利用者が管理責任をもつ「ソフトウェアの障害」です。利用者はOSやアプリケーションを自由に変更でき、その結果生じる不具合に関して事業者は制御できないためです。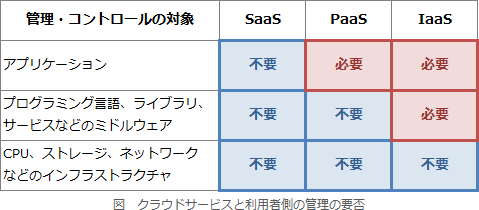
∴ウ:ソフトウェアの障害
