応用情報技術者過去問題 平成25年秋期 午後問3
⇄問題文と設問を画面2分割で開く⇱問題PDF問3 システムアーキテクチャ
サーバ仮想化に関する次の記述を読んで,設問1~4に答えよ。
E社は,関東地区を中心に事業を営む食料品の卸業者である。E社の顧客はスーパーマーケットであり,E社のWebサイトで顧客からの注文を24時間365日受け付けている。Webサイトで受け付けた注文は,E社の受注担当者が毎日8時~18時の間に受注確認を行い,受注確認ができた注文の商品を翌日の7時に出荷している。 E社のシステムは,顧客からの注文を受け付ける受注システム,仕入先へ商品の発注を行う発注システム,従業員の給与計算を行う総務システムの三つの情報システムから成る。各情報システムは,アプリケーションサーバ(以下,APサーバという)とデータベースサーバ(以下,DBサーバという)から構成されている。三つの情報システムは,個別のハードウェアによって構成されており,サーバの保守費用が高くなっている。
E社では,受注システムのハードウェアの保守期間満了を契機に,サーバの保守費用の削減を目的として,仮想化技術によって三つの情報システムのハードウェアを統合した新情報システム基盤を構築することにした。新情報システム基盤の構築は,E社の情報システム部のF君が担当することになった。
〔現行情報システムの構成〕
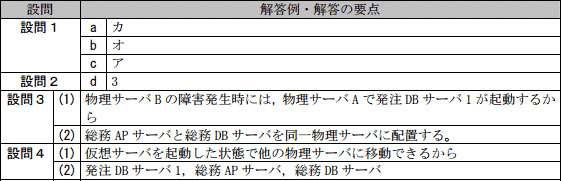
F君は,新情報システム基盤の構築に向けて,現行の三つの情報システムのハードウェア構成と,ピーク時におけるCPU利用率とメモリ利用率を調査した(表1)。
受注システムは,顧客が24時間365日注文できるように,冗長構成にしている。APサーバは,二つのAPサーバに負荷を分散して,一方のAPサーバにハードウェア障害が発生しても他方のAPサーバだけで縮退運転可能なa方式としている。また,DBサーバは,受注DBサーバ1を利用しており,受注DBサーバ1のハードウェア障害時には,あらかじめ起動してある受注DBサーバ2に自動的に切り替えるb方式としている。
発注システムは,APサーバについては受注システムと同様のa方式とし,DBサーバについては発注DBサーバ1のハードウェア障害時に手動で発注DBサーバ2を起動するc方式としている。
総務システムは,社外の顧客や仕入先に影響を与えないので,APサーバ,DBサーバそれぞれ1台の構成としている。
発注システムと総務システムについては,利用者がE社の社員であるので,ハードウェア点検やセキュリティパッチ適用のために,情報システムを停止させることが許容されている。 〔新情報システム基盤の構成案〕
〔新情報システム基盤の構成案〕
F君は,現行情報システムのハードウェア構成とピーク時利用率を基に,サーバ仮想化による新情報システム基盤の構成案を作成した(図1)。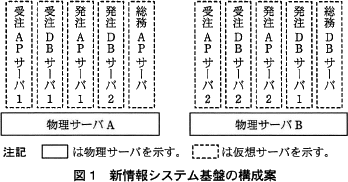 この構成案を採用した場合,ピーク時に物理サーバAとBに最低限必要なCPU数は同数になり,それぞれd個となる。メモリ量についても同じになり,それぞれ24Gバイトとなる。ここで,物理サーバAとBには,3.0GHzのCPUを用いることにする。
この構成案を採用した場合,ピーク時に物理サーバAとBに最低限必要なCPU数は同数になり,それぞれd個となる。メモリ量についても同じになり,それぞれ24Gバイトとなる。ここで,物理サーバAとBには,3.0GHzのCPUを用いることにする。
〔冗長構成の検討〕
E社が導入を予定している仮想化システムには,情報システムが利用可能な状態のまま仮想サーバを他の物理サーバに移動させる機能と,障害が発生した物理サーバで動作していた仮想サーバを他の物理サーバで自動的に再起動させる機能がある。ただし,他の物理サーバで自動的に再起動させる場合は,情報システムが再び利用可能になるまでに一定の時間を要する。なお,複数の仮想サーバを並行して再起動させる場合の再起動時間は,単一の仮想サーバの再起動時間と同等であるとする。
F君は,物理サーバのハードウェア障害時にも,片方の物理サーバで全仮想サーバが動作可能なように,物理サーバのCPU数とメモリ量を,ピーク時に必要な数量の2倍にする構成案をまとめた。
〔新情報システム基盤の構成案のレビュー〕
F君がまとめた新情報システム基盤の構成案をF君の上司にレビューしてもらったところ,次の2点の指摘を受けた。
〔新情報システム基盤の保守〕
E社の情報システム運用規程では,年1回のハードウェア点検と,必要に応じて実施するセキュリティパッチの適用が義務付けられている。ハードウェア点検では,点検対象のハードウェアを停止させ,ハードウェアを構成する部品に異常が無いことを確認する。また,セキュリティパッチについては,情報システムを構成するOSやミドルウェアにセキュリティパッチを適用する。セキュリティパッチの種類によっては,サーバの再起動が必要になる。
F君は,〔新情報システム基盤の構成案のレビュー〕で構成を確定した新情報システム基盤について,ハードウェア点検とセキュリティパッチの適用方法について検討を行った。この結果,①ハードウェア点検については,新情報システム基盤の導入によって,情報システムの停止や縮退運転をすることなく実施できることが分かった。しかし,②セキュリティパッチの適用については,現行情報システムと同様に,セキュリティパッチの種類によっては,情報システムの停止や縮退運転が必要であることが分かった。
E社は,関東地区を中心に事業を営む食料品の卸業者である。E社の顧客はスーパーマーケットであり,E社のWebサイトで顧客からの注文を24時間365日受け付けている。Webサイトで受け付けた注文は,E社の受注担当者が毎日8時~18時の間に受注確認を行い,受注確認ができた注文の商品を翌日の7時に出荷している。 E社のシステムは,顧客からの注文を受け付ける受注システム,仕入先へ商品の発注を行う発注システム,従業員の給与計算を行う総務システムの三つの情報システムから成る。各情報システムは,アプリケーションサーバ(以下,APサーバという)とデータベースサーバ(以下,DBサーバという)から構成されている。三つの情報システムは,個別のハードウェアによって構成されており,サーバの保守費用が高くなっている。
E社では,受注システムのハードウェアの保守期間満了を契機に,サーバの保守費用の削減を目的として,仮想化技術によって三つの情報システムのハードウェアを統合した新情報システム基盤を構築することにした。新情報システム基盤の構築は,E社の情報システム部のF君が担当することになった。
〔現行情報システムの構成〕
F君は,新情報システム基盤の構築に向けて,現行の三つの情報システムのハードウェア構成と,ピーク時におけるCPU利用率とメモリ利用率を調査した(表1)。
受注システムは,顧客が24時間365日注文できるように,冗長構成にしている。APサーバは,二つのAPサーバに負荷を分散して,一方のAPサーバにハードウェア障害が発生しても他方のAPサーバだけで縮退運転可能なa方式としている。また,DBサーバは,受注DBサーバ1を利用しており,受注DBサーバ1のハードウェア障害時には,あらかじめ起動してある受注DBサーバ2に自動的に切り替えるb方式としている。
発注システムは,APサーバについては受注システムと同様のa方式とし,DBサーバについては発注DBサーバ1のハードウェア障害時に手動で発注DBサーバ2を起動するc方式としている。
総務システムは,社外の顧客や仕入先に影響を与えないので,APサーバ,DBサーバそれぞれ1台の構成としている。
発注システムと総務システムについては,利用者がE社の社員であるので,ハードウェア点検やセキュリティパッチ適用のために,情報システムを停止させることが許容されている。
F君は,現行情報システムのハードウェア構成とピーク時利用率を基に,サーバ仮想化による新情報システム基盤の構成案を作成した(図1)。
〔冗長構成の検討〕
E社が導入を予定している仮想化システムには,情報システムが利用可能な状態のまま仮想サーバを他の物理サーバに移動させる機能と,障害が発生した物理サーバで動作していた仮想サーバを他の物理サーバで自動的に再起動させる機能がある。ただし,他の物理サーバで自動的に再起動させる場合は,情報システムが再び利用可能になるまでに一定の時間を要する。なお,複数の仮想サーバを並行して再起動させる場合の再起動時間は,単一の仮想サーバの再起動時間と同等であるとする。
F君は,物理サーバのハードウェア障害時にも,片方の物理サーバで全仮想サーバが動作可能なように,物理サーバのCPU数とメモリ量を,ピーク時に必要な数量の2倍にする構成案をまとめた。
〔新情報システム基盤の構成案のレビュー〕
F君がまとめた新情報システム基盤の構成案をF君の上司にレビューしてもらったところ,次の2点の指摘を受けた。
- 指摘1
- 新情報システム基盤の導入によって,発注DBサーバ2は不要になる。
- 指摘2
- 総務システムが利用する仮想サーバの配置を見直すだけで,総務システムが利用できなくなる頻度を,F君がまとめた構成案よりも低下させることができる。
〔新情報システム基盤の保守〕
E社の情報システム運用規程では,年1回のハードウェア点検と,必要に応じて実施するセキュリティパッチの適用が義務付けられている。ハードウェア点検では,点検対象のハードウェアを停止させ,ハードウェアを構成する部品に異常が無いことを確認する。また,セキュリティパッチについては,情報システムを構成するOSやミドルウェアにセキュリティパッチを適用する。セキュリティパッチの種類によっては,サーバの再起動が必要になる。
F君は,〔新情報システム基盤の構成案のレビュー〕で構成を確定した新情報システム基盤について,ハードウェア点検とセキュリティパッチの適用方法について検討を行った。この結果,①ハードウェア点検については,新情報システム基盤の導入によって,情報システムの停止や縮退運転をすることなく実施できることが分かった。しかし,②セキュリティパッチの適用については,現行情報システムと同様に,セキュリティパッチの種類によっては,情報システムの停止や縮退運転が必要であることが分かった。
設問1
本文中のa~cに入れる適切な字句を解答群の中から選び,記号で答えよ。
a,b,c に関する解答群
- コールドスタンバイ
- シェアードエブリシング
- シェアードナッシング
- フェールセーフ
- ホットスタンバイ
- ロードシェア
解答入力欄
- a:
- b:
- c:
解答例・解答の要点
- a:カ
- b:オ
- c:ア
解説
E社では、受注管理を行う受注システム、発注管理を行う発注システム、給与計算などを行う総務システムの3つのシステムが稼働してます。それぞれのシステムはアプリケーションソフトを動かすアプリケーションサーバとデータを管理するデータベースサーバの2台のサーバ構成を基本としています。受注システムと発注システムは、さらに、負荷分散とサーバの障害時の縮退運転を目的として、サーバの2重化を行っており、全部で10台のサーバが稼働しています。この問題は、このようなサーバの構成や障害時の切り替え方式の名称を問う問題です。解答できるか否かは用語を知っているかどうかがすべてになります。
選択肢のそれぞれの用語について、確認しましょう。
障害時に縮退運転をするとあるので、フェールソフトやフォールバックが入りそうですが解答群にはありません。解答群のうち、負荷分散という点に着目すれば「ロードシェア」しか適切な解答はありません。
∴a=カ:ロードシェア
〔bについて〕
〔現行情報システムの構成〕には「受注DBサーバ1のハードウェア障害時には,あらかじめ起動してある受注DBサーバ2に自動的に切り替える」と記載されています。待機系を起動しておき、障害発生時にシームレスに処理の引き継ぎを行う冗長構成は「ホットスタンバイ」です。
∴b=オ:ホットスタイバイ
〔cについて〕
〔現行情報システムの構成〕には「発注DBサーバ1のハードウェア障害時に手動で発注DBサーバ2を起動する」と記載されています。待機系を停止しておき、障害発生時に待機系の起動から始める冗長構成は「コールドスタンバイ」です。
∴c=ア:コールドスタンバイ
選択肢のそれぞれの用語について、確認しましょう。
- コールドスタンバイ
- 機器の構成を2重化するデュプレックス構成の1つです。通常時は片方の機器(主系)のみで運用を行い、もう一方の機器(待機系)は起動させずに停止状態にしておきます。障害発生時には、待機系を起動し、データを移行するなどの切り替え時間が発生するため、即時の切り替えはできません。
- シェアードエブリシング
- 複数のノードが1つのディスクを共有するActive-Active構成のアーキテクチャです。複数のノード間で負荷分散を行い、障害発生時にはフェールオーバーで処理を引き継ぐことでダウンタイムを最小限に抑えます。どのノードも全てのデータにアクセスできるため障害に強い利点がありますが、ノード追加に伴う共有ディスクへのアクセス競合の増加がボトルネックとなり、ノード追加による処理能力向上がダイレクトに得られないデメリットもあります。
- シェアードナッシング
- ノードごとに占有するディスク、データが割り当てられているActive-Active構成のアーキテクチャです。複数のノードに処理を分散することにより処理能力を向上させることができます。ディスクアクセスの競合が発生しないためスケールアウトの弊害が少なく、ノードを追加すればするほど性能が(線形的に)向上する利点がありますが、あるDBサーバに障害が発生した場合はそれに付随するディスクのデータが孤立してしまうというデメリットもあります。
- フェールセーフ
- 障害発生時の対処方式で、障害が発生した場合に安全になるように制御する方式です。「踏切が故障したら遮断したままにし侵入による事故を防ぐ」、「速度制御装置が故障したら停止させる」など例が挙げられます。
- ホットスタイバイ
- 機器の構成を2重化するデュプレックス構成の1つです。通常時は片方の機器(主系)のみで運用を行うのはコールドスタンバイと同様ですが、ホットスタンバイでは、もう片方の機器(待機系)も稼働させて、常に稼働系との同期を行わせています。これによりコールドスタンバイに比べて、障害発生時の切り替え時間が早くなります。一方で、常に二重化された機器(2倍)が稼働していることからソフトウェアライセンスも2倍かかるなどコスト面では高くなります。
- ロードシェア
- 複数の機器を用意して、ロードバランサなどにより処理を振り分けて負荷を分散する方式です。ロードバランサが複数機器それぞれに対して定期的な正常稼働確認(ハートビートチェック、ヘルスチェック)を行い、障害を検知した機器を切り離すことにより、構成する機器の一部に障害が発生しても、縮退運転を可能にすることができます。
障害時に縮退運転をするとあるので、フェールソフトやフォールバックが入りそうですが解答群にはありません。解答群のうち、負荷分散という点に着目すれば「ロードシェア」しか適切な解答はありません。
∴a=カ:ロードシェア
〔bについて〕
〔現行情報システムの構成〕には「受注DBサーバ1のハードウェア障害時には,あらかじめ起動してある受注DBサーバ2に自動的に切り替える」と記載されています。待機系を起動しておき、障害発生時にシームレスに処理の引き継ぎを行う冗長構成は「ホットスタンバイ」です。
∴b=オ:ホットスタイバイ
〔cについて〕
〔現行情報システムの構成〕には「発注DBサーバ1のハードウェア障害時に手動で発注DBサーバ2を起動する」と記載されています。待機系を停止しておき、障害発生時に待機系の起動から始める冗長構成は「コールドスタンバイ」です。
∴c=ア:コールドスタンバイ
設問2
本文中のdに入れる適切な数値を整数で答えよ。ここで,物理サーバのCPUの1GHz当たりの処理能力は,現行情報システムのCPUの1GHz当たりの処理能力と同等とする。CPUの処理能力は,CPU周波数に比例するものとする。また,物理サーバで仮想サーバを動作させるための仮想化システムに必要なCPU数,メモリ量は考慮しないものとする。
解答入力欄
- d: 個
解答例・解答の要点
- d:3
解説
設問の条件に従って、表1の現行システムと図1の新システムの構成を基に計算をして答えを導きます。問題文にて、物理サーバAとBの必要CPU数は同じだと示してくれていますので、どちらか一方の計算だけでよいことになります。
物理サーバ1のピーク時におけるCPU処理量を考えます。
8[GHz]÷3[GHz]=2.666…
最小限必要なCPUは小数点以下を切り上げた「3個」が正解です。
∴d=3
物理サーバ1のピーク時におけるCPU処理量を考えます。
- 受注APサーバ1 … 2[GHz]×2[個]×20%=0.8[GHz]
- 受注DBサーバ1 … 2[GHz]×4[個]×40%=3.2[GHz]
- 発注APサーバ1 … 1.5[GHz]×2[個]×40%=1.2[GHz]
- 発注DBサーバ2 … 1.5[GHz]×4[個]×40%=2.4[GHz]
- 総務APサーバ … 1[GHz]×2[個]×20%=0.4[GHz]
- 合計 … 0.8+3.2+1.2+2.4+0.4=8[GHz]
8[GHz]÷3[GHz]=2.666…
最小限必要なCPUは小数点以下を切り上げた「3個」が正解です。
∴d=3
設問3
〔新情報システム基盤の構成案のレビュー〕について,(1),(2)に答えよ。
- 指摘1について,発注DBサーバ2が不要な理由を40字以内で述べよ。
- 指摘2について,総務システムが利用できなくなる頻度を低下させるためには,仮想サーバの配置をどのように変更すればよいか。35字以内で述べよ。
解答入力欄
解答例・解答の要点
- 物理サーバBの障害発生時には,物理サーバAで発注DBサーバ1が起動するから (37文字)
- 総務APサーバと総務DBサーバを同一物理サーバに配置する (28文字)
解説
- 〔冗長構成の検討〕には「障害が発生した物理サーバで動作していた仮想サーバを他の物理サーバで自動的に再起動させる機能がある」とあります。この機能を発注DBサーバに適用すれば、もし物理サーバBに障害が発生して主系の発注DBサーバ1が停止した場合でも、発注DBサーバ1を物理サーバAに移して再起動すれば済みます。発注DBサーバはコールドスタンバイ構成ですから、待期系の発注サーバ2を起動しても、発注サーバ1を移動して再起動しても、処理が再開されるまでの時間は変わりません。したがって、発注サーバ2は不要であると考えられます。
∴物理サーバBの障害発生時には,物理サーバAで発注DBサーバ1が起動するから - 総務システムのサーバは2台の物理サーバに分かれて配置されているので、正常稼働するには2台の物理サーバがともに動いていなければなりません。しかし、総務システムのサーバをどちらかの物理サーバにまとめれば、その物理サーバ1台が稼働していればよいことになります。機器の稼働率が同じであれば、2台の機器がともに稼働し続ける確率よりも、1台の機器が稼働し続ける確率の方が高いため、総務システムを片方の物理サーバにまとめた方が故障率は低下すると言えます。
∴総務APサーバと総務DBサーバを同一物理サーバに配置する
設問4
〔新情報システム基盤の保守〕について,(1),(2)に答えよ。
解答入力欄
解答例・解答の要点
- 仮想サーバを起動した状態で他の物理サーバに移動できるから (28文字)
- 発注DBサーバ1,総務APサーバ,総務DBサーバ
解説
- 〔冗長構成の検討〕には以下の記載があります。
- 情報システムが利用可能な状態のまま仮想サーバを他の物理サーバに移動させる機能…がある
- 片方の物理サーバで全仮想サーバが動作可能なように,物理サーバのCPU数とメモリ量を,ピーク時に必要な数量の2倍にする構成案をまとめた
∴仮想サーバを起動した状態で他の物理サーバに移動できるから - サーバが冗長化(二重化)されている場合、一方を停止してセキュリティパッチを適用することができるのでシステムを停止する必要がありません。一方、冗長化されていないサーバを使用しているシステムでは、システム自体を停止しなければなりません。
新情報システム基盤の構成案で冗長化されていないのは「総務APサーバ」と「総務DBサーバ」、そしてF君の上司のレビューにより発注DBサーバ2が不要と判断されたことにより、単一になってしまう「発注DBサーバ1」の3つです。
∴発注DBサーバ1,総務APサーバ,総務DBサーバ