
応用情報技術者過去問題 令和3年春期 午後問6
⇄問題文と設問を画面2分割で開く⇱問題PDF問6 データベース
経営分析システムのためのデータベース設計に関する次の記述を読んで,設問1~4に答えよ。
P社は,個人向けのカーシェアリングサービスを運営するMaaS(Mobility as a Service)事業者である。シェアリングのニーズが高い大都市の地区を中心に,500駐車場で約2,000台の自動車(以下,車両という)を貸し出している。P社には本社のほかに,各地区でのサービス運営を担当する支社が10社ある。本社はサービス全体を統括しており,新サービスの企画やマーケティングなどを行っている。支社は貸出管理システムを用いて現場で車両の貸出管理業務を行っている。
本社では,サービス運営状況を多角的な観点でタイムリーに把握して,適切な意思決定を行うために,貸出管理システムのデータをソースとする経営分析システムを構築することになった。本社の情報システム部のQさんはデータエンジニアに任命され,データサイエンティストであるRさんとプロジェクトを推進することになった。
〔データソースの調査〕
貸出管理システムには,貸出予約及び貸出実績のデータが過去5年間分蓄積されている。貸出管理システムのデータモデルの抜粋を図1に示す。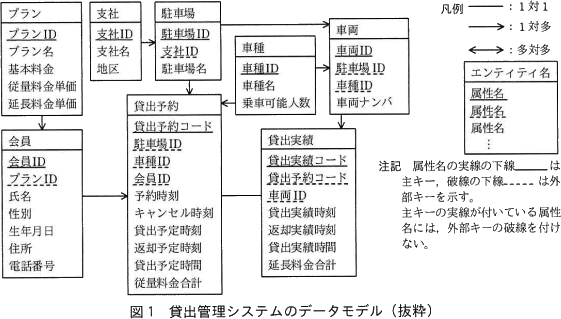 利用希望者はあらかじめP社の会員になり,いずれかのプランに加入しておく必要がある。プランごとに基本料金(月額),従量料金及び延長料金(いずれも10分単位)の単価が決まっている。会員が車両を借りたいときは,P社のホームページで借りたい日時や駐車場,車種などを選択し,貸出を予約する。貸出や返却の実績時刻が予約時の内容と異なる場合であっても,貸出予約の情報は修正しない。従量料金合計は予約時に指定された貸出予定時間を基に算出する。予約時に指定した返却予定時刻より早い時刻に返却しても,従量料金合計は減算しない。予約時に指定した返却予定時刻より遅い時刻に返却した場合は遅延返却として扱う。遅延返却は後の時間帯に予約している別の会員の迷惑となるので,超過した時間については従量料金よりも高い延長料金によって延長料金合計を算出する。これによって,遅延返却の発生件数(以下,遅延返却発生件数という)の低減を図っている。毎月末に当月の基本料金,従量料金合計及び延長料金合計を合算して,翌月に会員に請求する。
利用希望者はあらかじめP社の会員になり,いずれかのプランに加入しておく必要がある。プランごとに基本料金(月額),従量料金及び延長料金(いずれも10分単位)の単価が決まっている。会員が車両を借りたいときは,P社のホームページで借りたい日時や駐車場,車種などを選択し,貸出を予約する。貸出や返却の実績時刻が予約時の内容と異なる場合であっても,貸出予約の情報は修正しない。従量料金合計は予約時に指定された貸出予定時間を基に算出する。予約時に指定した返却予定時刻より早い時刻に返却しても,従量料金合計は減算しない。予約時に指定した返却予定時刻より遅い時刻に返却した場合は遅延返却として扱う。遅延返却は後の時間帯に予約している別の会員の迷惑となるので,超過した時間については従量料金よりも高い延長料金によって延長料金合計を算出する。これによって,遅延返却の発生件数(以下,遅延返却発生件数という)の低減を図っている。毎月末に当月の基本料金,従量料金合計及び延長料金合計を合算して,翌月に会員に請求する。
貸出管理システムのデータベースでは,データモデルのエンティティ名を表名にし,属性名を列名にして,適切なデータ型で表定義した関係データベースによって,データを管理している。時刻はTIMESTAMP型,年月日はDATE型で定義されている。
また,P社ではKPIの一つとして車両稼働率を重視している。車両稼働率とは,各車両における1日当たりの貸出実績時間の割合である。平均車両稼働率の目標データは,表計算ソフトのデータとして,年月日別・駐車場別・車種別に過去3年間分が蓄積されており,それ以前のデータは破棄されている。
〔業務要件の把握〕
P社の経営企画部では,車両の追加整備計画の立案を検討している。Rさんは経営企画部にヒアリングを行い,経営分析システムの業務要件を把握した。業務要件の抜粋を図2に示す。
Qさんは,データソースの調査結果を踏まえて,図2の業務要件の実現可能性を評価した。その結果,①業務要件の一部は経営分析システムの運用開始直後には実現できないことが判明した。対応方針を経営企画部と協議した結果,業務要件は変更せず,運用開始直後の分析は,実現可能な範囲で行うことで合意した。 〔経営分析システムのデータモデル設計〕
〔経営分析システムのデータモデル設計〕
次に,Qさんは図2の業務要件を基に,経営分析システムのデータモデルを多次元データベースとして設計した。多次元データベースの実装には,データモデルのエンティティ名を表名にし,属性名を列名にして,適切なデータ型で表定義した関係データベースを用いることにした。列指向データベースは用いず,データを行単位で扱う行指向データベースを用いることにした。問合せの処理性能を考慮して,データモデルの構造にはa構造を採用した。経営分析システムのデータモデルの抜粋を図3に示す。
経営分析システムには,最長で過去5年間分のデータを蓄積することにした。
年月日の週と曜日は,事前に定義したSQLのユーザ定義関数を用いて取得できる。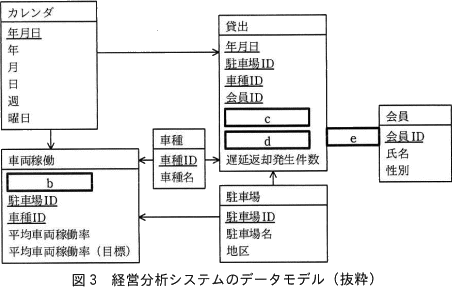 〔データ加工処理の開発〕
〔データ加工処理の開発〕
貸出管理システムのデータベースから経営分析システムのデータベースへのデータ連携時に,一部のデータを加工する必要がある。Qさんは,データ加工処理用のデータベースを用意し,データ加工を行うバッチ処理プログラムを開発した。図4のSQL文は,そこで用いられている図3の貸出表の遅延返却発生件数データを作成するためのものである。ここで,TIMESTAMP_TO_DATE関数は,指定されたTIMESTAMP型の時刻をDATE型の年月日に変換するユーザ定義関数である。
バッチ処理プログラムでは,図4のSQL文で作成したデータを貸出表に挿入する際,遅延返却発生件数が0件のレコードに対する処理も別途行うようになっている。 〔分析のレスポンス性能の改善〕
〔分析のレスポンス性能の改善〕
性能検証を実施したところ,分析対象期間を過去複数年間,時間軸を月別として人気車種及び遅延返却発生件数を分析する場合,種々の分析に時間が掛かり過ぎるので改善してほしいという要望が経営企画部から挙がった。経営分析システムのデータベースのインデックスは既に適切に作成している。分析のレスポンス性能を改善するために,Qさんは②データマートとして集計表を追加した。
P社は,個人向けのカーシェアリングサービスを運営するMaaS(Mobility as a Service)事業者である。シェアリングのニーズが高い大都市の地区を中心に,500駐車場で約2,000台の自動車(以下,車両という)を貸し出している。P社には本社のほかに,各地区でのサービス運営を担当する支社が10社ある。本社はサービス全体を統括しており,新サービスの企画やマーケティングなどを行っている。支社は貸出管理システムを用いて現場で車両の貸出管理業務を行っている。
本社では,サービス運営状況を多角的な観点でタイムリーに把握して,適切な意思決定を行うために,貸出管理システムのデータをソースとする経営分析システムを構築することになった。本社の情報システム部のQさんはデータエンジニアに任命され,データサイエンティストであるRさんとプロジェクトを推進することになった。
〔データソースの調査〕
貸出管理システムには,貸出予約及び貸出実績のデータが過去5年間分蓄積されている。貸出管理システムのデータモデルの抜粋を図1に示す。
貸出管理システムのデータベースでは,データモデルのエンティティ名を表名にし,属性名を列名にして,適切なデータ型で表定義した関係データベースによって,データを管理している。時刻はTIMESTAMP型,年月日はDATE型で定義されている。
また,P社ではKPIの一つとして車両稼働率を重視している。車両稼働率とは,各車両における1日当たりの貸出実績時間の割合である。平均車両稼働率の目標データは,表計算ソフトのデータとして,年月日別・駐車場別・車種別に過去3年間分が蓄積されており,それ以前のデータは破棄されている。
〔業務要件の把握〕
P社の経営企画部では,車両の追加整備計画の立案を検討している。Rさんは経営企画部にヒアリングを行い,経営分析システムの業務要件を把握した。業務要件の抜粋を図2に示す。
Qさんは,データソースの調査結果を踏まえて,図2の業務要件の実現可能性を評価した。その結果,①業務要件の一部は経営分析システムの運用開始直後には実現できないことが判明した。対応方針を経営企画部と協議した結果,業務要件は変更せず,運用開始直後の分析は,実現可能な範囲で行うことで合意した。
次に,Qさんは図2の業務要件を基に,経営分析システムのデータモデルを多次元データベースとして設計した。多次元データベースの実装には,データモデルのエンティティ名を表名にし,属性名を列名にして,適切なデータ型で表定義した関係データベースを用いることにした。列指向データベースは用いず,データを行単位で扱う行指向データベースを用いることにした。問合せの処理性能を考慮して,データモデルの構造にはa構造を採用した。経営分析システムのデータモデルの抜粋を図3に示す。
経営分析システムには,最長で過去5年間分のデータを蓄積することにした。
年月日の週と曜日は,事前に定義したSQLのユーザ定義関数を用いて取得できる。
貸出管理システムのデータベースから経営分析システムのデータベースへのデータ連携時に,一部のデータを加工する必要がある。Qさんは,データ加工処理用のデータベースを用意し,データ加工を行うバッチ処理プログラムを開発した。図4のSQL文は,そこで用いられている図3の貸出表の遅延返却発生件数データを作成するためのものである。ここで,TIMESTAMP_TO_DATE関数は,指定されたTIMESTAMP型の時刻をDATE型の年月日に変換するユーザ定義関数である。
バッチ処理プログラムでは,図4のSQL文で作成したデータを貸出表に挿入する際,遅延返却発生件数が0件のレコードに対する処理も別途行うようになっている。
性能検証を実施したところ,分析対象期間を過去複数年間,時間軸を月別として人気車種及び遅延返却発生件数を分析する場合,種々の分析に時間が掛かり過ぎるので改善してほしいという要望が経営企画部から挙がった。経営分析システムのデータベースのインデックスは既に適切に作成している。分析のレスポンス性能を改善するために,Qさんは②データマートとして集計表を追加した。
設問1
本文中の下線①について,実現できない業務要件を40字以内で具体的に答えよ。
解答入力欄
解答例・解答の要点
- システム稼働後2年間は,過去5年間分の平均車両稼働率の目標比を表示できない (37文字)
解説
図2中の業務要件には、以下の記述があります。
平均車両稼働率の"前年同月比"は運用開始直後でも過去5年分が分析可能ですので、実現できないのは「平均車両稼働率の目標比」だけです。以上より、「運用開始直後は、過去5年間分の平均車両稼働率の目標比を分析できない」旨の解答が適切となります。
∴システム稼働後2年間は,過去5年間分の平均車両稼働率の目標比を表示できない
- 表計算ソフトのデータを用いて,平均車両稼働率の目標比や前年同期比を分析できること。
- 過去5年間について,分析対象期間を柔軟に変更して,期間による傾向の違いを分析できること。
平均車両稼働率の"前年同月比"は運用開始直後でも過去5年分が分析可能ですので、実現できないのは「平均車両稼働率の目標比」だけです。以上より、「運用開始直後は、過去5年間分の平均車両稼働率の目標比を分析できない」旨の解答が適切となります。
∴システム稼働後2年間は,過去5年間分の平均車両稼働率の目標比を表示できない
設問2
〔経営分析システムのデータモデル設計〕について,(1),(2)に答えよ。
- 本文中のaに入れる適切な字句を解答群の中から選び,記号で答えよ。
- 図3中のb~eに入れる適切なエンティテイ間の関連及び属性名を答えよ。なお,エンティティ間の関連及び属性名の表記は図1の凡例及び注記に倣うこと。
(※正誤判定の都合上、主キー属性は{属性名}、外部キー属性は(属性名)と入力してください)
a に関する解答群
- 3層スキーマ
- オブジェクト指向
- スタースキーマ
- スノーフレークスキーマ
- 第3正規形
- 非正規形
解答入力欄
- a:
- b:
- c:
- d:
- e:
解答例・解答の要点
- a:ウ
- b:年月日
- c:年代
- d:貸出実績件数
- e:←
解説
- 〔aについて〕
ビジネス戦略の意思決定などの目的で、データソースからデータ分析用のデータを抽出し整理したデータの集合体を「データウェアハウス」と言います。
データウェアハウスでは多くの場合、データソースから抽出した分析対象の(トランザクション)データを少数のテーブル(ファクトテーブル)に格納します。そして、ファクトテーブルの外部キーから参照する主キーを持つマスタ系テーブル(ディメンションテーブル)に分析軸を格納します。このようにファクトテーブルを中心にして、ディメンションテーブルが周囲に配置されるデータモデルの構造を「スタースキーマ」と言い、関係データベースにおける多次元データベースの実装の一つです。スタースキーマでは、表の結合を少なくして処理を高速化するため、ディメンションテーブルはあえて冗長データをもたせて第2正規化までに留める(階層化しない)ことが一般的です。図3のデータモデルだと、車両稼働、貸出エンティティがファクトテーブル、カレンダ、車種、会員、駐車場エンティティがディメンションテーブルに相当します。また、ディメンションテーブルが1階層に留まっているためスタースキーマ構造と判断できます。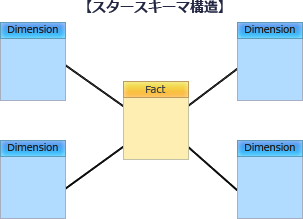
∴a=ウ:スタースキーマ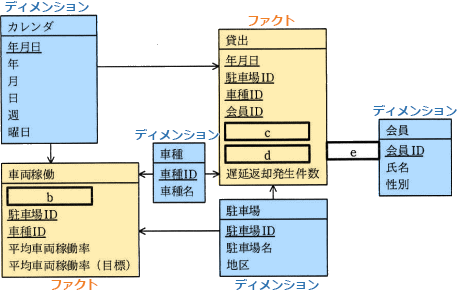
- 3層スキーマはデータモデルより前のデータベースの構成(概念スキーマ、外部スキーマ、内部スキーマ)を示すものであるため、不適切です。
- 関係データベースを用いているため、データモデルはオブジェクト指向構造ではありません。
- 正しい。
- スノーフレークスキーマは、スタースキーマのディメンションテーブルを正規化(階層化)した構造です。図3のデータモデルではディメンションテーブルが1階層に留まっているので、スノーフレークスキーマではありません。
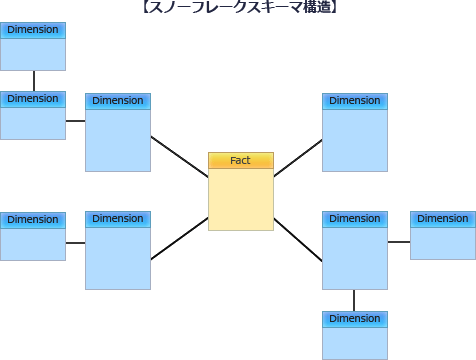
- 駐車場エンティティに属性"地区"がありますが、図1のデータモデルを見ると、"地区"は駐車場ID→支社IDで一意に決まる属性です。推移的関数従属性が残っているので、第3正規形にはなっていません。
- 非正規形では関係データベースにテーブル定義ができないため、不適切です。
- 〔bについて〕
カレンダエンティティと車両稼働エンティティの間には1対多の関係があります。エンティティ同士は同じ主キーと外部キーを持たせることによって関連付けますが、カレンダエンティティの主キー"年月日"に相当する属性が車両稼働エンティティにはないので追加する必要があります。図2には「これらのいずれにおいても,年月,月別,日別,週別,曜日別といった時間軸で傾向を分析できること」が業務要件として示されているため、ある1日の駐車場・車種別の平均車両稼働率がわかる必要があります。
よって、車両稼働エンティティでは属性"年月日","駐車場ID","車種ID"によりレコードが一意に特定されることがわかります。したがって、車両稼働エンティティの属性"年月日"は主キーの一部であり、空欄には「年月日」が当てはまります。
∴b=年月日
〔cdについて〕
図2の業務要件には「地区別の人気車種,会員の性別・年代別の人気車種、(中略)駐車場別・会員別の遅延返却発生件数を分析できること。なお,貸出実績の件数(以下,貸出実績件数という)が多い場合を人気車種であるとみなす」とあります。この分析を行うために不足している属性を考えることになります。
"地区"は駐車場エンティティに、"性別"は会員エンティティにあるので問題ありません。しかし"年代"についてはどこにもデータがありません。また会員エンティティには生年月日がないので、貸出当時の会員の年代を年月日との演算で求めることもできません。したがって、まずは「年代」を追加する必要があります。
もう一つの属性は、人気車種を分析するときに必要となる「貸出実績件数」です。とちらも主キー属性ではありません。
∴cd=年代、貸出実績件数(順不同)
〔eについて〕
会員エンティティと貸出エンティティには共通の属性「会員ID」があります。この属性「会員ID」は、会員エンティティ側では主キーであり、会員を一意に特定します。また、貸出エンティティ側では他のキーとともに主キーを構成し、貸出を一意に特定しており、同時に外部キーです。明らかに同一の会員が異なる日に車両を借りることが考えられるので、貸出エンティティには同一の会員IDをもつ複数のレコード存在しえます。したがって、会員エンティティと貸出エンティティのカーディナリティは1対多であり、空欄には「←」が当てはまります。
∴e=←
※一般にエンティティA,B間に関係があることがわかっている場合、エンティティAの主キーの属性がエンティティBでも存在すれば、エンティティBのその属性は外部キーであることが形式的に判断できます。
※原則として、ある主キーをもつエンティティと、その主キーを外部キーに持つエンティティのカーディナリティ(多重度)は「1対多」です。
設問3
〔データ加工処理の開発〕について,(1),(2)に答えよ。
- 図4中のf,gに入れる適切な字句を答えよ。なお,表の列名には必ずその表の相関名を付けて答えよ。
- 図4のSQL文を実行するべき頻度を2字以内で答えよ。
解答入力欄
- f:
- g:
解答例・解答の要点
- f:INNER JOIN 貸出実績 J ON R.貸出予約コード =
- g:GROUP BY R.貸出予定年月日,R.駐車場ID,R.車種ID,R.会員ID
- 日次 (2文字)
解説
- 〔fについて〕
空欄の直後の「J.貸出予約コード」やWHERE句の「J.返却実績時刻」の記述から、貸出予約テーブルの取得結果で構成される副問合せR以外に、「J」と別名(相関名)が付けられたテーブルが登場し、副問合せRと結合されることがわかります。「貸出予約コード」や「返却実績時刻」という列をもつテーブルは貸出実績テーブルです。貸出予約テーブルと貸出実績テーブルは"貸出予約コード"列で関係付けられています。したがって、空欄には「INNER JOIN 貸出実績 J ON R.貸出予約コード =」が当てはまります。
LEFT OUTER JOINと考えた方もいるかもしれませんが、図1を見ると貸出予約エンティティと貸出実績エンティティは1対1の関係です。貸出予約エンティティ対応する貸出実績エンティティは必ず存在するため、外部結合にする理由は何らありません。
∴f=INNER JOIN 貸出実績 J ON R.貸出予約コード =
〔gについて〕
SELECT句に集計関数COUNTがあることから、GROUP BY句が必要だと判断できます。GROUP BY句があるときSELECT句の列として指定できるのは、GROUP BY句で指定した列(式を含む)と集計関数に限定されます。逆から言えば、少なくともSELECT句に記述されている集計キー以外の列は、GROUP BY句でも指定されている必要があります。
図4のSELECT句には取得対象の列として、R.貸出予定年月日、R.駐車場ID、R.車種ID、R.会員ID、COUNT(*)の5つが指定されていますから、前4つの列はGROUP BY句でグループ化の対象としなければなりません。したがって、空欄には「GROUP BY R.貸出予定年月日, R.駐車場ID, R.車種ID, R.会員ID」が当てはまります。
∴g=GROUP BY R.貸出予定年月日,R.駐車場ID,R.車種ID,R.会員ID - 図4のSQL文は、遅延返却発生件数を集計するためのものです。図2の業務要件には「遅延返却発生件数については前日までの実績を翌営業日の朝に確認できること」とあり、この業務要件を満たすためには毎日0時から営業開始までの間に図4のSQL文を実行しなくてはなりません。実行する頻度を2文字で答えるとなると「日次」や「毎日」「日毎」などが当てはまります。
∴日次
設問4
本文中の下線②について,追加した集計表の主キーを答えよ。
解答入力欄
解答例・解答の要点
- 年月,駐車場ID,車種ID,会員ID
解説
データマートとは、データウェアハウスに格納されたデータから特定の用途に必要なデータだけを取り出し、構築する小規模なデータベースです。
年月ごとの貸出実績件数や遅延返却発生件数を取得するには、少なくとも貸出テーブルとカレンダテーブルを結合し、"年"列と"月"列でGROUP BYする必要があります。分析に時間が掛かるのは、リクエストの度にテーブル結合とGROUP BYが実行されているからであると考えられるので、レスポンスを改善する方法として、データマートとしてあらかじめ年月ごとに集計したデータベースを用意しておく方法があります。つまり、新たに作成するテーブルは貸出テーブルの"年月日"列を"年月"列に変えたものです。したがって、そのテーブルの主キーは「年月,駐車場ID,車種ID,会員ID」です。
∴年月,駐車場ID,車種ID,会員ID
年月ごとの貸出実績件数や遅延返却発生件数を取得するには、少なくとも貸出テーブルとカレンダテーブルを結合し、"年"列と"月"列でGROUP BYする必要があります。分析に時間が掛かるのは、リクエストの度にテーブル結合とGROUP BYが実行されているからであると考えられるので、レスポンスを改善する方法として、データマートとしてあらかじめ年月ごとに集計したデータベースを用意しておく方法があります。つまり、新たに作成するテーブルは貸出テーブルの"年月日"列を"年月"列に変えたものです。したがって、そのテーブルの主キーは「年月,駐車場ID,車種ID,会員ID」です。
∴年月,駐車場ID,車種ID,会員ID
